Hofmeister Technical Introduction
The Hofmeister XIX project involved research by a team of musicologists including Nicholas Cook and Liz Robinson (Department of Music, Royal Holloway, University of London) and Digital Humanities specialists including Elena Pierazzo, Paul Vetch, José Miguel Vieira and Paul Spence (Centre for Computing in the Humanities, King's College London). The project created an on-line publication of the Hofmeister Monatsberichte – monthly catalogues of printed music - for the years 1829-1900. The project’s main research aim was to create a digital scholarly resource which would enable study of the catalogues; the principal technical research methodology was based on a text encoding approach. The major outcomes include a text-based publication which integrates closely with high-quality facsimile images of the original Monatsberichte on the website of the Austrian National Library and which allows semantically encoded concepts (including composers, publishers and publication places) to be indexed and searched.
This project began with a number of technical research challenges
- The size of the data: well over eight million words, 330,000 entries and nearly 20,000 pages of text.
- The existence of highly structured entries that also demonstrate a great variation in form.
- The existence of text in different languages and with different alphabets (Cyrillic, for instance) that needed to be a transliterated in order to enable Cyrillic-aware searching
- The requirement that the encoding should support a representation of the transcription that largely preserves the layout of the original in order to meet scholarly expectations.
- The need to integrate closely with the Austrian National Library’s web publication of high-quality facsimile images of the originals
This technical introduction is aimed at the non-specialist and gives a taste of the technologies used and why we think they were necessary. For those interested in more information, we will provide a detailed technical report.
Facilitating digital publication: ‘text markup’
The technology that underpins the project is called XML (Extensible Markup Language), a now ubiquitous international standard for encoding and exchanging data. Although used nowadays in a wide range of operations involving data exchange, such as the transmission of information from one financial database to another, XML has firm roots in the humanities.
In fact, in research projects involving textual materials, XML can prove very useful for modelling humanities knowledge for a number of reasons, including its independence from any particular computer platform or software, the extremely robust basis it provides for encoding document-based materials and the fact that it potentially facilitates the generation of a wide variety of different representations of the encoded materials afterwards. This is no accident, since XML developed in part as a technology to facilitate digital publication.
One of the core principles in XML is that the representation of the structural and semantic content of a text should be kept separate from its presentation. The core information about the text is applied by means of a system of XML ‘tags’ that encode parts of the text (see figure below), and any ‘visualisation’ of the text that is required for publishing purposes is then produced in a separate process. This is particularly useful in humanities scholarship, because it allows academics to concentrate on the structure and content of the source materials, and issues around scholarly interpretation of the text, leaving issues of presentation to the later publication processes.

- Monatsberichte encoding sample
Text Encoding Initiative: creating ‘added value’ for the core textual materials
In this project we elected to use a particular set of XML specifications called TEI (Text Encoding Initiative), an international and interdisciplinary standard that since 1994 has “been widely used by libraries, museums, publishers, and individual scholars to present texts for online research, teaching, and preservation.”1 TEI XML has the technical rigour which allows computers to carry out complex processing, while at the same time being flexible and relatively easy for the average scholar to use, whether or not they have experience in using computers.
TEI allows us to encode scholarly assertions about the source materials in a complex and fine-grained manner, exposing detail in large repositories of information. So, in the case of this project, a textual markup scheme was created (using customised TEI) to include particular aspects of the bibliographical records (bibliographic entries were distinguished from albums and 'wips', i.e. 'works in parts'), distinguishing, for instance, authors from composers or encoding musical keys and opus numbers.
The regularizations of names
To index and search names of persons, publishing companies or places we decided at a very early stage that we needed to regularise the instances found in the source material in order to connect occurrences like “Budapest” and “Budàpest” or "J.S. Bach" with "Jo. Bach" and "Bach, Johan Sebastian". To regularise names we created lists of:
- Composers
- Publication places
- Publishers etc.
- Countries
- Hofmeister classifications
- Registration numbers
- Musical keys
- Opus numbers
Such lists were intended to store a regularised version and all the forms retrieved from the encoded source material together with all the instances of a given entity.
Though we chose a simple model for our authority lists (or thesauri), in Hofmeister XIX the workflow for thesaurus creation and population is rather complex:
- core material was encoded using XML- indexable concepts were given preliminary markup as part of this process
- instances of indexable concepts in the XML core material batches were extracted using XSLT scripts
- we performed automatic regularisation for some of the extracted instances: Perl scripts were used to regularise automatically personal names from the Name + Surname layout (typical of the source material) to the Surname + Name layout (necessary for the alphabetical sorting of indices), while other scripts regularised the musical key and opus numbers into standard formats
- we then processed (and partially regularised) instances, re-introducing them into spreadsheets (divided per batches) for editing purposes. The spreadsheet solution was chosen to help scholars in sorting and easily managing data on their own.
- each extracted or revised instance was then matched to the appropriate regularised form
- we then processed several spreadsheets to produce a single XML file and from this generated a unique identifier for each entry
- we added a key attribute based on the identifier of the thesaurus to the relevant elements in the core material
- we indexed both the keyed core material and thesauri into a Ereuna search framework to be used for the indices and search facilities on the publication web site.
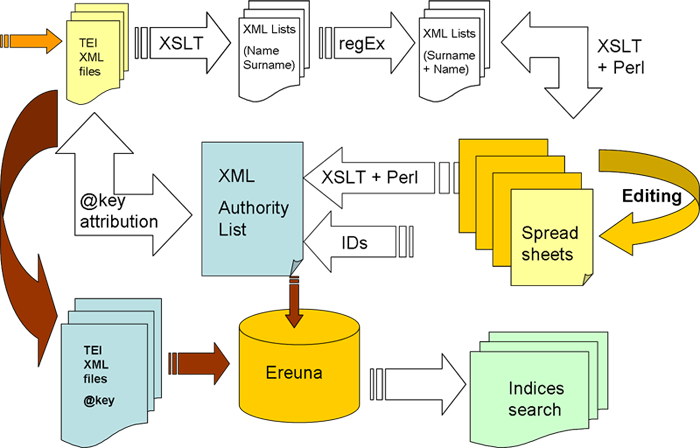
- Thesauri work flow
Search and Indices
Hofmeister’s search facilities and indices were developed using Ereuna. Ereuna is a framework, based on Apache Lucene, whose purpose is to speed up the development of search facilities for web applications.
The framework can be used with a wide range of source materials (XML and non-XML bases). It reduces the need for specific programming skills (such as experience in using Apache Lucene), and is language-independent.
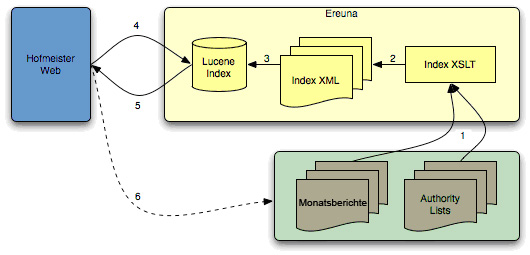
- Ereuna work flow
Ereuna works in the following way:
- A stylesheet (written in the XSLT transformation language) is applied to the XML source documents, and this creates indexable XML documents, one for each entry (bibl, wip, album, etc) in the XML source documents;
- The index XML documents are processed by Apache Lucene to create a searchable index;
- The application uses the index to execute searches and return search results (arrow 5 in the figure);
- Included in the search results is information that was copied directly from the source XML documents. This allows for a faster display of the search results.
Initially the indices were built with data from a MySQL database together with data from authority files. For performance reasons the indices were later rebuilt using Ereuna.
Footnotes
- 1 .
- http://www.tei-c.org/index.xml (accessed December 15, 2007)Back to context...